йӣ·иҫҫиҮӘйҖӮеә”жіўжқҹеҪўжҲҗпјҡеҹәдәҺFPGAзҡ„QRD+WBSз®—жі•
йӣ·иҫҫе’Ңж— зәҝз”өзі»з»ҹд»ҺжЁЎжӢҹдҝЎеҸ·еӨ„зҗҶйҖҗжёҗеҸ‘еұ•еҲ°ж•°еӯ—дҝЎеҸ·еӨ„зҗҶпјҢдҝғиҝӣдәҶжіўжқҹеҪўжҲҗжҠҖжңҜзҡ„еҸ‘еұ•пјҢ并з”ұжӯӨеёҰжқҘдәҶжіўжқҹеҪўжҲҗжҠҖжңҜзҡ„йқ©ж–°гҖӮй«ҳзІҫеәҰзҡ„жіўжқҹж•°еӯ—еҢ–еӨ„зҗҶиғҪеҠӣпјҢеҸҜд»ҘеҪ»еә•ж”№еҸҳжңӘжқҘзҡ„е•Ҷз”Ёе’ҢеҶӣз”Ёйӣ·иҫҫзі»з»ҹи®ҫи®ЎгҖӮ
иҮӘйҖӮеә”жіўжқҹеҪўжҲҗз®—жі•йҮҮз”Ёжө®зӮ№з®—жі•иҝӣиЎҢдҝЎеҸ·еӨ„зҗҶпјҢйҖҡиҝҮеҗҢж—¶еҸ‘е°„еӨҡдёӘзӮ№жіўжқҹеҗ„иҮӘиҝӣиЎҢе®һж—¶зӣ®ж Үи·ҹиёӘпјҢеҸҜд»ҘжҸҗй«ҳйӣ·иҫҫжҖ§иғҪгҖӮ
ж”№иҝӣзҡ„ж јжӢүе§Ҷ-ж–ҪеҜҶзү№(MGS)зҹ©йҳөеҲҶи§Ј(QRD)е’ҢжқғеҖјеӣһд»Јз®—жі•(WBS)жҳҜйӣ·иҫҫDSPиҠҜзүҮзҡ„йҮҚиҰҒз®—жі•пјҢеҸҜд»ҘдҪҝйӣ·иҫҫеңЁжҠ‘еҲ¶ж—Ғз“ЈгҖҒеҷӘеЈ°е’Ңе№Іжү°зҡ„еҗҢж—¶иҮӘйҖӮеә”жіўжқҹеҪўжҲҗгҖӮиҝҷдәӣз®—жі•йңҖиҰҒйқһеёёй«ҳзҡ„жҜҸз§’жө®зӮ№иҝҗз®—ж¬Ўж•°(FLOPS)гҖӮ
Xilinxе…¬еҸёзҡ„FPGAиҠҜзүҮзҡ„жө®зӮ№иҝҗз®—иғҪеҠӣпјҢжҜ”е•Ҷз”ЁGPUгҖҒDSPе’ҢеӨҡж ёCPUиҠҜзүҮиҰҒй«ҳеҮ дёӘж•°йҮҸзә§гҖӮ
HLSжҳҜXilinxе…¬еҸёзҡ„Vivado®и®ҫи®ЎеҘ—件зҡ„дёҖдёӘж ҮеҮҶе·Ҙе…·пјҢж”ҜжҢҒжң¬ең°CиҜӯиЁҖзј–з Ғи®ҫи®ЎгҖӮиҮӘйҖӮеә”жіўжқҹеҪўжҲҗзҡ„ж ёеҝғжҳҜдёҖз§Қжө®зӮ№зҹ©йҳөжұӮйҖҶз®—жі•пјҢиҝҷз§Қз®—жі•зӣ®еүҚеҸҜйҖҡиҝҮжң¬ең°C/C++иҜӯиЁҖжҲ–Xilinxе…¬еҸёзҡ„Vivado HLS SystemCиҜӯиЁҖзј–з Ғи®ҫи®ЎгҖӮ
жң¬ж–Үе…іжіЁзҡ„жҳҜдёҖдёӘеӨҚжө®зӮ№еҮҪж•°пјҢеҸҜеҸҳеӨ§е°Ҹзҡ„ж”№иҝӣзҡ„ж јжӢүе§Ҷ-ж–ҪеҜҶзү№(MGS)зҹ©йҳөеҲҶи§Ј(QRD)е’ҢжқғеҖјеӣһд»Јз®—жі•(WBS)пјҢеӨҚжө®зӮ№еҮҪж•°еӨ§е°Ҹдёә128x64гҖӮ
дёҖгҖҒеј•иЁҖ
зӣ®еүҚпјҢеӨ§еӨҡж•°йӣ·иҫҫйғҪйҮҮз”ЁдәҶжҹҗз§Қзұ»еһӢзҡ„иҮӘйҖӮеә”ж•°еӯ—жіўжқҹеҪўжҲҗжҠҖжңҜгҖӮжҺҘ收波жқҹеҪўжҲҗжҰӮеҝөеҰӮеӣҫ1жүҖзӨәгҖӮ
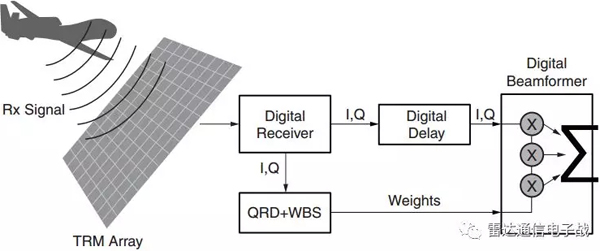
еӣҫ1гҖҒиҮӘйҖӮеә”ж•°еӯ—жіўжқҹеҪўжҲҗ
йӣ·иҫҫи®ҫи®ЎеҚ з”Ёзҡ„еёҰе®Ҫи¶ҠжқҘи¶Ҡй«ҳпјҢиҰҒжұӮжҺҘ收系з»ҹжӣҙеҠ еҸҜйқ ең°жҠ‘еҲ¶д»ҘдёӢеҮ ж–№йқўпјҡдёҖжҳҜеҷӘеЈ°жәҗе№Іжү°пјҢдәҢжҳҜзӣ®ж Үд»ҘеӨ–зҡ„еӨ©зәҝж—Ғз“ЈпјҢдёүжҳҜж•Ңж–№е№Іжү°дҝЎеҸ·зҡ„е№Іжү°пјҢеӣӣжҳҜж–°еһӢйӣ·иҫҫжҠҖжңҜзҡ„е®ҪеёҰе®Ҫзү№жҖ§еј•иө·зҡ„“жқӮжіў”гҖӮ
еңЁе®ҡеҗ‘жҺ§еҲ¶жҜҸдёӘеӨ©зәҝйҳөеҲ—жңҹй—ҙеҝ…йЎ»е®ҢжҲҗдёҠиҝ°еӨ„зҗҶпјҡеҲҶеҲ«еӨ„зҗҶгҖҒеҗҢж—¶еӨ„зҗҶжҲ–иҖ…е®һж—¶еӨ„зҗҶгҖӮеңЁз»ҷе®ҡзҡ„ж—¶й—ҙиҢғеӣҙеҶ…пјҢйҖҡиҝҮеҚ•е…ғзә§еӨ„зҗҶеҸҜд»ҘжҲҗеҠҹе®ҢжҲҗиҝҷдәӣд»»еҠЎпјҢеҚіеҲҶеҲ«жҲ–еҗҢж—¶еҜ№жҜҸдёӘеӨ©зәҝеҚ•е…ғзҡ„жҺҘ收дҝЎеҸ·иҝӣиЎҢж•°еӯ—еҢ–еӨ„зҗҶгҖӮ
иҮӘйҖӮеә”ж•°еӯ—жіўжқҹеҪўжҲҗжҳҜеҚ•е…ғзә§еӨ„зҗҶзҡ„йҮҚиҰҒйғЁеҲҶгҖӮжң¬ж–ҮйҮҚзӮ№д»Ӣз»ҚдәҶиҮӘйҖӮеә”жіўжқҹеҪўжҲҗжҠҖжңҜпјҢд»ҘеҸҠеҰӮдҪ•йҮҮз”ЁXilinxе…¬еҸёзҡ„FPGAиҠҜзүҮжһ„е»әдёҖз§ҚжҜ”дј з»ҹйӣ·иҫҫзі»з»ҹжҲҗжң¬жӣҙдҪҺгҖҒз»“жһ„жӣҙеӨҚжқӮгҖҒеҠҹиҖ—жӣҙеӨ§гҖҒдёҠеёӮж—¶й—ҙжӣҙзҹӯзҡ„жіўжқҹжҚ·еҸҳйӣ·иҫҫзі»з»ҹгҖӮ
еҲ©з”Ёжң¬ж–ҮеҸҷиҝ°зҡ„жҠҖжңҜе’ҢXilinxе…¬еҸёзҡ„组件пјҢйҖҡиҝҮи®Ўз®—еӨҚжө®зӮ№еҮҪж•°зҡ„иҮӘйҖӮеә”жқғеҖјпјҢеҸҜд»Ҙе®һзҺ°жіўжқҹжҚ·еҸҳйӣ·иҫҫгҖӮиҝҷдәӣжқғеҖјеҹәдәҺеүҚдёҖдёӘи„үеҶІйҮҚеӨҚй—ҙйҡ”(PRI)зј“еӯҳзҡ„еӨҚжқӮжҺҘ收дҝЎеҸ·ж ·жң¬еӯҗйӣҶгҖӮи®Ўз®—иҝҷдәӣжқғеҖјзҡ„жҢ‘жҲҳеңЁдәҺпјҢйңҖиҰҒиҝӣиЎҢеӨҚзҹ©йҳөжұӮйҖҶпјҢеңЁжҺҘ收дёӢдёҖдёӘи„үеҶІйҮҚеӨҚй—ҙйҡ”ж•°жҚ®д№ӢеүҚи§Је…¬ејҸ1гҖӮ
йңҖиҰҒдёҖдёӘзЎ®е®ҡзҡ„гҖҒдҪҺ延иҝҹзҡ„зҹ©йҳөеӨ§е°ҸпјҢиҜҘзҹ©йҳөеӨ§е°ҸжҳҜйӣ·иҫҫзі»з»ҹйңҖжұӮзҡ„еҮҪж•°гҖӮдј з»ҹдёҠпјҢиҝҷз§Қз®—жі•жҳҜз”ұи®ёеӨҡ并иЎҢCPUиҠҜзүҮжү§иЎҢзҡ„пјҢзЎ®дҝқеңЁдёӢдёҖдёӘи„үеҶІйҮҚеӨҚй—ҙйҡ”д№ӢеүҚе®ҢжҲҗжө®зӮ№иҝҗз®—гҖӮ
иҖғиҷ‘еҲ°и®ёеӨҡйӣ·иҫҫ/з”өеӯҗжҲҳзі»з»ҹзҡ„е°әеҜёгҖҒйҮҚйҮҸе’ҢеҠҹзҺҮ(SWaP)йҷҗеҲ¶пјҢCPU/GPUиҠҜзүҮдёҚжҳҜе®ҢжҲҗиҝҷдәӣиҝҗз®—зҡ„жңҖдҪійҖүжӢ©гҖӮXilinxе…¬еҸёзҡ„FPGAиҠҜзүҮйҮҮз”Ёзҡ„硬件иҫғе°‘пјҢеҸҜд»Ҙжӣҙжңүж•Ҳең°жү§иЎҢй«ҳ并иЎҢзҡ„жө®зӮ№з®—жі•гҖӮ
Xilinxе…¬еҸёзҡ„FPGAиҠҜзүҮе…·жңүе…је®№жҖ§пјҢйӣ·иҫҫи®ҫи®ЎиҖ…еҸҜд»ҘйҖҡиҝҮе…је®№зҡ„I/Oж ҮеҮҶ(дҫӢеҰӮJESD204BгҖҒSRIOгҖҒPCIe®зӯү)еӨ„зҗҶеӨ§йҮҸзҡ„ж•°жҚ®пјҢ然еҗҺе®һж—¶и®Ўз®—FPGAиҠҜзүҮзҡ„иҮӘйҖӮеә”жқғеҖјгҖӮйңҖиҰҒжұӮи§Јзҡ„зәҝжҖ§ж–№зЁӢеңЁеҰӮеӣҫ1жүҖзӨәзҡ„QRD+WBSз®—жі•еҠҹиғҪжЎҶеӣҫдёӯпјҢе…¬ејҸ1зҡ„ж•°еӯҰиЎЁиҫҫејҸдёәпјҡ

x=жұӮи§Јзҡ„еӨҚеҗ‘йҮҸпјҢеҸҳжҲҗиҮӘйҖӮеә”жқғеҖјпјҢеӨ§е°Ҹ(n,1)
b=жңҹжңӣе“Қеә”жҲ–еҜјеҗ‘зҹўйҮҸпјҢеӨ§е°Ҹ(m,1)
дёәдәҶжұӮи§ЈxпјҢдёҚиғҪзӣҙжҺҘз”ЁbйҷӨд»ҘAгҖӮж”№иҝӣзҡ„ж јжӢүе§Ҷ-ж–ҪеҜҶзү№(MGS)зҹ©йҳөеҲҶи§Ј(QRD)з®—жі•йңҖиҰҒи®Ўз®—зҹ©йҳөжұӮйҖҶгҖӮж”№иҝӣзҡ„ж јжӢүе§Ҷ-ж–ҪеҜҶзү№(MGS)зҹ©йҳөеҲҶи§Ј(QRD)з®—жі•еҝ…йЎ»йҮҮз”Ёжө®зӮ№иҝҗз®—пјҢд»ҘдҝқжҢҒиҮӘйҖӮеә”жқғеҖјзҡ„зІҫеәҰгҖӮ
дәҢгҖҒVivado HLSжҰӮиҝ°
Vivado HLSе·Ҙе…·йҮҮз”ЁC/C++иҜӯиЁҖдҪңдёә硬件и®ҫи®Ўзҡ„жәҗзЁӢеәҸпјҢе°ҶйӘҢиҜҒж—¶й—ҙеҮҸе°‘еҮ дёӘж•°йҮҸзә§пјҢжҳҫи‘—еҠ еҝ«дәҶиҝҗз®—йҖҹеәҰгҖӮй’ҲеҜ№зЎ¬д»¶зҡ„зӣ®ж Үз®—жі•пјҢйҖҡеёёйңҖиҰҒиҫ“е…ҘеӨ§йҮҸзҡ„жөӢиҜ•еҗ‘йҮҸйӣҶпјҢд»ҘзЎ®дҝқжӯЈзЎ®зҡ„зі»з»ҹе“Қеә”гҖӮ
йҮҮз”ЁRTLе’ҢеҹәдәҺдәӢ件зҡ„RTLжЁЎжӢҹеҷЁж—¶пјҢеҸҜиғҪйңҖиҰҒж•°е°Ҹж—¶з”ҡиҮіж•°еӨ©жүҚиғҪе®ҢжҲҗжЁЎжӢҹгҖӮ然иҖҢпјҢйҮҮз”ЁC/C++иҜӯиЁҖж—¶пјҢжЁЎжӢҹйҖҹеәҰеҸҜд»ҘеҠ еҝ«10000еҖҚпјҢиғҪеӨҹеңЁеҮ з§’жҲ–иҖ…еҮ еҲҶй’ҹеҶ…е®ҢжҲҗжЁЎжӢҹгҖӮжҜҸеӨ©йҖҡиҝҮжӣҙеӨҡзҡ„дәӨдә’и®ҫи®ЎпјҢи®ҫи®ЎиҖ…иғҪеӨҹд»Ҙжӣҙеҝ«зҡ„йӘҢиҜҒж—¶й—ҙеҠ йҖҹз ”еҸ‘гҖӮеҰӮеӣҫ2жүҖзӨәгҖӮ
йҷӨдәҶйӘҢиҜҒж—¶й—ҙжӣҙеҝ«д№ӢеӨ–пјҢVivado HLSиҝҳж”ҜжҢҒй«ҳйҳ¶и®ҫи®ЎжЈҖзҙўпјҢз”ЁжҲ·еҸҜд»ҘеңЁдёҚдҝ®ж”№жәҗд»Јз Ғзҡ„жғ…еҶөдёӢпјҢеҝ«йҖҹжЈҖзҙўеӨҡдёӘ硬件дҪ“зі»з»“жһ„зҡ„дёҚеҗҢеҢәеҹҹ并иҝӣиЎҢжҖ§иғҪжқғиЎЎгҖӮиҝҷеҸҜд»ҘйҖҡиҝҮеҗҲжҲҗжҢҮд»Өе®һзҺ°пјҢдҫӢеҰӮloop unrollingе’Ңpipeline insertionгҖӮ
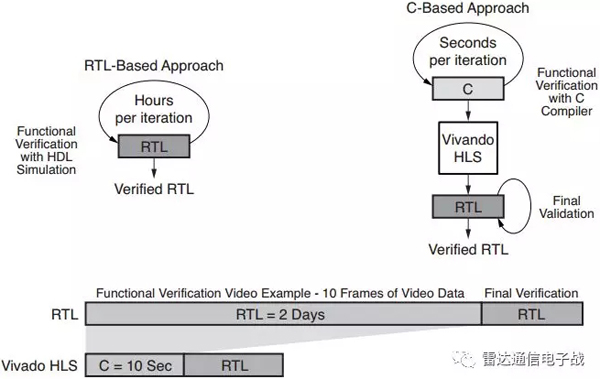
еӣҫ2гҖҒеҹәдәҺRTLе’ҢеҹәдәҺCиҜӯиЁҖзҡ„иҝӯд»Јз ”еҸ‘ж—¶й—ҙ
йҮҮз”Ёж ҮеҮҶзҡ„ж•°еӯҰеҮҪж•°пјҢVivado HLSеҠ иҪҪдәҶC/C++иҜӯиЁҖзј–зЁӢзҡ„зәҝжҖ§д»Јж•°еҮҪж•°еә“пјҢйҖҡиҝҮHLSеҸҜд»ҘеҗҲжҲҗиҝҷдәӣеҮҪж•°еә“пјҢ并дјҳеҢ–з»“жһңгҖӮз ”еҸ‘иҝҷдәӣеҠҹиғҪжҳҜдёәдәҶи®©з”ЁжҲ·е……еҲҶеҲ©з”ЁVivado HLSзҡ„и®ҫи®ЎжЈҖзҙў(еҢ…жӢ¬loop unrollingе’Ңpipeline register insertion)пјҢдҪҝз”ЁжҲ·иғҪеӨҹйқһеёёзҒөжҙ»ең°з”ҹжҲҗж»Ўи¶іи®ҫи®ЎйңҖжұӮзҡ„硬件дҪ“зі»з»“жһ„гҖӮ
з”ЁжҲ·еҸҜд»Ҙдҝ®ж”№иҝҷдәӣеҮҪж•°зҡ„жәҗд»Јз ҒпјҢиҝҷдәӣеҠҹиғҪдҪңдёәи®ҫи®Ўе·ҘдҪңзҡ„иө·зӮ№пјҢеңЁжңҖз»ҲеҗҜз”Ёж—¶жңүжӣҙеӨ§зҡ„зҒөжҙ»жҖ§гҖӮеҮҪж•°еә“еҢ…жӢ¬д»ҘдёӢеҠҹиғҪе’Ңж”ҜжҢҒзҡ„ж•°жҚ®зұ»еһӢ(иҜҰи§ҒиЎЁ1)пјҡ
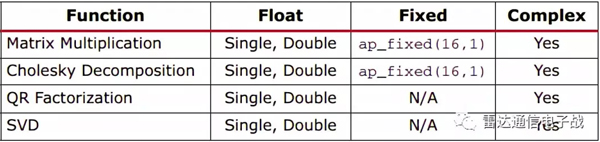
иЎЁ1гҖҒVivado HLSдёӯзҡ„еҮҪж•°/ж•°жҚ®зұ»еһӢ
дёүгҖҒQRDе’ҢWBSз®—жі•
QRDе°ҶеӨҚзҹ©йҳөAиҪ¬жҚўдёәпјҡ
QпјҡжҳҜдёҖдёӘеӨ§е°Ҹ(mпјҢn)зҡ„жӯЈдәӨзҹ©йҳө
RпјҡжҳҜеӨ§е°Ҹ(mпјҢn)зҡ„дёҠдёүи§’зҹ©йҳөпјҢжҲ–еҸідёүи§’зҹ©йҳөгҖӮе®ғз§°дёәдёүи§’еҪўпјҢдёӢж–№зҡ„дёүи§’еҪўеҖјйғҪдёә0гҖӮиҝҷж ·дҪҝжұӮи§Јxзҡ„иҝҗз®—йҖҹеәҰеҫҲеҝ«гҖӮ
дёәз®ҖеҚ•иө·и§ҒпјҢMGSз®—жі•йҮҮз”ЁOctaveжҲ–MATLAB®д»Јз ҒпјҢеҰӮеӣҫ3жүҖзӨәгҖӮ

еӣҫ3гҖҒMGS QRDз®—жі•
йҖҡиҝҮеӣһд»ЈпјҢи§ЈеҮәxгҖӮ
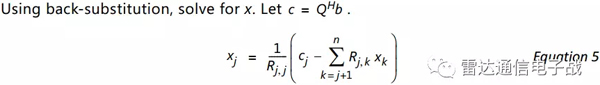
еӣӣгҖҒеҹәдәҺCPUе’ҢFPGAиҠҜзүҮзҡ„жіўжқҹеҪўжҲҗдҪ“зі»з»“жһ„
еҪ“еҠҹиғҪдёҚйҖӮеҗҲеҚ•дёӘи®ҫеӨҮж—¶пјҢеҗҺжһңеҸҜиғҪйқһеёёдёҘйҮҚпјҢеҜјиҮҙеҶ…еӯҳгҖҒжҺҘеҸЈгҖҒжңүж•Ҳйқўз§ҜгҖҒйӣҶжҲҗж—¶й—ҙгҖҒжҲҗжң¬е’ҢеҠҹзҺҮзҡ„еўһеҠ гҖӮ
(дёҖ)еӨҡCPUиҠҜзүҮдҪ“зі»з»“жһ„
еҪ“йҮҮз”ЁеӨҡдёӘCPUиҠҜзүҮзҡ„иҖҒж–№жі•е®һзҺ°иҮӘйҖӮеә”жіўжқҹеҪўжҲҗж—¶пјҢеҸҜиғҪдјҡеҮәзҺ°дёҠиҝ°жғ…еҶөгҖӮйҖҡиҝҮQRD+WBSз®—жі•еҜ№16дёӘйҖҡйҒ“иҝӣиЎҢжіўжқҹеҪўжҲҗеӨ§зәҰйңҖиҰҒ3.5msгҖӮеҹәдәҺCPUиҠҜзүҮзҡ„и®ҫи®ЎдёҚд»…дёҚйҖӮеҗҲеҚ•дёӘи®ҫеӨҮпјҢе®ғйңҖиҰҒжӣҙж·ұе…Ҙзҡ„зі»з»ҹи®ҫи®ЎгҖҒи®ӨиҜҒе’ҢйӣҶжҲҗпјҢдё”еҠҹиҖ—еҫҲеӨ§гҖӮ
и®әиҜҒзҡ„з»“жһңжҳҜпјҢжҜҸдёӘCPUиҠҜзүҮж ёйңҖиҰҒ250msжү§иЎҢ128×64жө®зӮ№ж•°зҡ„еӨҚжқӮQRD+WBSз®—жі•(иҝҷжҳҜдҝқе®Ҳдј°и®ЎпјҢеӣ дёәжІЎжңүиҖғиҷ‘еҶ…еӯҳеӯҳеҸ–е’Ңи°ғеәҰж—¶й—ҙ)гҖӮз”Ё250msйҷӨд»Ҙ3.5msпјҢйңҖиҰҒ72дёӘCPUиҠҜзүҮж ёжү§иЎҢQRDз®—жі•гҖӮCPUиҠҜзүҮи®ҫи®Ўж—¶еҜ№зі»з»ҹи®ҫи®ЎиҖ…иҝӣиЎҢдәҶйҷҗеҲ¶пјҢеҸӘйў„з•ҷдәҶйқһеёёжңүйҷҗзҡ„дёҖз»„еҶ…еӯҳе’ҢеӨ–йғЁжҺҘеҸЈгҖӮ

еӣҫ4гҖҒйҮҮз”Ё18дёӘCPUиҠҜзүҮ(72ж ё)зҡ„иҮӘйҖӮеә”жіўжқҹеҪўжҲҗ
6дёӘCPUиҠҜзүҮжқҝ(жҜҸдёӘиҠҜзүҮжқҝе®үиЈ…3дёӘCPU иҠҜзүҮпјҢжҜҸдёӘCPUиҠҜзүҮжңү4ж ёпјҢеҗҲи®Ў72ж ё)пјҢеҠ дёҠдёҖдёӘжіўжқҹеҪўжҲҗдё»жқҝпјҢжҖ»е…ұ7дёӘжқҝпјҢжҜҸдёӘжқҝеҠҹиҖ—зәҰ200з“ҰпјҢжҖ»еҠҹиҖ—зәҰ1400з“ҰгҖӮеҪ“然пјҢеҸҜд»ҘйҮҮз”Ёжӣҙй«ҳзҡ„CPUиҠҜзүҮж—¶й’ҹйў‘зҺҮ(еҠҹиҖ—жӣҙеӨ§)пјҢдҪҶжҳҜCPUиҠҜзүҮзҡ„еҠҹиҖ—д»ҚжІЎжңүFPGAиҠҜзүҮзҡ„еҠҹиҖ—еҘҪгҖӮеҰӮеӣҫ4жүҖзӨәпјҢиҝҷжҳҜдёҖдёӘCPUиҠҜзүҮзҡ„дҪ“зі»з»“жһ„пјҢйңҖиҰҒ18дёӘCPUиҠҜзүҮгҖӮ
(дәҢ)Xilinxе…¬еҸёзҡ„еҚ•дёӘFPGAиҠҜзүҮдҪ“зі»з»“жһ„
Xilinxе…¬еҸёзҡ„FPGAиҠҜзүҮеҫҲе®№жҳ“е®үиЈ…еңЁVirtex7 FPGAиҠҜзүҮз»„дёӯгҖӮеҚ•дёӘFPGAиҠҜзүҮе®үиЈ…еңЁз”өи·ҜжқҝдёҠпјҢиҜҘз”өи·Ҝжқҝиҝҳе®үиЈ…дәҶеӨ–йғЁеҶ…еӯҳе’Ңе…¶д»–иҫ…еҠ©еҠҹиғҪиЈ…зҪ®пјҢеҚ•дёӘз”өи·Ҝжқҝзҡ„жҖ»еҠҹиҖ—зәҰ75з“ҰгҖӮ
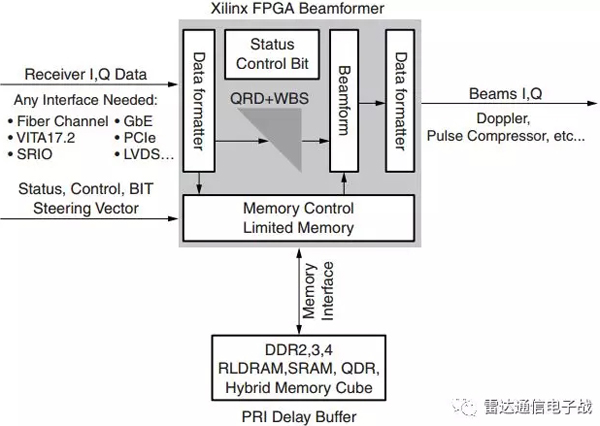
еӣҫ5гҖҒйҮҮз”ЁеҚ•дёӘVirtex-7 FPGAиҠҜзүҮзҡ„иҮӘйҖӮеә”жіўжқҹеҪўжҲҗ
еңЁи§ЈеҶізӣёеҗҢй—®йўҳж—¶пјҢдёҺVPXеә•жқҝе®үиЈ…18дёӘCPUиҠҜзүҮзӣёжҜ”(еҰӮеңЁеӨҡCPUиҠҜзүҮдҪ“зі»з»“жһ„дёӯеҸҷиҝ°зҡ„йӮЈж ·)пјҢжҳҫ然CPUиҠҜзүҮзҡ„еҠҹиҖ—дёҺFPGAиҠҜзүҮзҡ„еҠҹиҖ—дёҚеҢ№й…ҚгҖӮ
дә”гҖҒйҮҮз”ЁVivadoжү§иЎҢMGS QRD+WBSз®—жі•
Vivado HLSдҪҝд»»дҪ•з®—жі•йғҪеҸҜд»ҘйҖҡиҝҮC/C++иҜӯиЁҖжҲ–SystemCиҜӯиЁҖзј–зЁӢпјҢе®ғдёәXilinxе…¬еҸёзҡ„жүҖжңүFPGAиҠҜзүҮзҡ„Vivadoе·Ҙе…·жөҒпјҢеҲӣе»әдәҶдёҖдёӘзҒөжҙ»гҖҒеҸҜ移жӨҚгҖҒеҸҜеҚҮзә§зҡ„ж ёгҖӮи®ҫи®ЎжөҒзЁӢеҰӮеӣҫ6жүҖзӨәгҖӮ

еӣҫ6гҖҒиҮӘйҖӮеә”жіўжқҹеҪўжҲҗзҡ„и®ҫи®ЎжөҒзЁӢ
з”ұдәҺMATLABеҸҜд»Ҙзј–иҜ‘C/ C++иҜӯиЁҖпјҢз§°дёәMEX (MATLABеҸҜжү§иЎҢзЁӢеәҸ)пјҢз”ЁжҲ·еҸҜд»Ҙи°ғз”ЁC/ C++д»Јз ҒпјҢиҖҢдёҚз”Ёи°ғз”Ёзӯүж•Ҳзҡ„MATLABеҮҪж•°гҖӮиҝҷж„Ҹе‘ізқҖеҸӘжңүдёҖдёӘдё»жЁЎеһӢе’Ңд»Јз ҒпјҢеӨ§еӨ§еҮҸе°‘дәҶжөӢиҜ•е’ҢйӣҶжҲҗзҡ„и®ҫи®ЎгҖӮи®ҫи®Ўж—¶й—ҙйҖҡеёёдёәеҮ дёӘжңҲеҲ°еҮ еӨ©пјҢдёҺзј–еҶҷVHDL/Verilogд»Јз ҒзӣёжҜ”пјҢе‘Ҫд»ӨйӣҶеҮҸе°‘дәҶгҖӮ
и®ҫи®Ўж—¶й—ҙзҡ„еҮҸе°‘жәҗиҮӘд»ҘдёӢдёӨдёӘж–№йқўпјҡ
1. йҖҡиҝҮеҸҜжү§иЎҢж–Ү件иҝҗиЎҢзҡ„C/ C++иҜӯиЁҖжЁЎжӢҹпјҢеҸӘйңҖиҰҒеҮ з§’й’ҹе°ұеҸҜд»ҘйӘҢиҜҒи®ҫи®Ўзҡ„еҸҚеә”ж—¶й—ҙе’Ңж•°еҖјгҖӮй—Ёзә§RTLжЁЎжӢҹжҳҜиҝӯд»Јзҡ„пјҢйҖҹеәҰж…ў10000еҖҚгҖӮеӣ жӯӨпјҢдёҖж—ҰеҸ‘зҺ°й”ҷиҜҜйңҖиҰҒз«ӢеҚізә жӯЈпјҢ然еҗҺеңЁRTLдёӯйҮҚж–°жЁЎжӢҹгҖӮ
иҝҷз§ҚеҫӘзҺҜз”ҡиҮідјҡеҜјиҮҙжңҖз®ҖеҚ•зҡ„и®ҫи®Ўд№ҹдјҡеҪұе“ҚжҲҗжң¬е’ҢиҝӣеәҰгҖӮVivado HLSзҡ„и®ҫ计第дёҖж¬ЎжҳҜжӯЈзЎ®зҡ„гҖӮз”ұдәҺеҠ еҝ«дәҶзі»з»ҹйӣҶжҲҗж—¶й—ҙпјҢеңЁи®ҫи®Ўйҳ¶ж®өжӣҙе®№жҳ“е°Ҫж—©еҸ‘зҺ°и®ҫи®Ўй”ҷиҜҜгҖӮ
2. йҮҮз”ЁC/ C++иҜӯиЁҖжҲ–SystemCиҜӯиЁҖжЁЎеһӢи®ҫи®ЎпјҢиҝҷж„Ҹе‘ізқҖи®ҫи®ЎжҖ»жҳҜеҸҜ移жӨҚгҖҒзҒөжҙ»е’ҢеҸҜеҚҮзә§зҡ„гҖӮи®ҫи®ЎиҖ…дёҚдјҡжӢҳжіҘдәҺзү№е®ҡзҡ„FPGAиҠҜзүҮжҲ–иҠҜзүҮз»„гҖӮ
з”ЁжҲ·еҸҜд»Ҙз«ӢеҚіжӣҙжҚўFPGAиҠҜзүҮз©әй—ҙпјҢдёәиҝҷдёӘи®ҫи®ЎжҢ‘йҖүжңҖйҖӮеҗҲзҡ„иҠҜзүҮ(дёҚйңҖиҰҒзҢңжөӢ)пјҢеӣ дёәHLSе·Ҙе…·зҡ„иҫ“еҮәе…¬еёғдәҶPFGAиҠҜзүҮзҡ„ж—¶й’ҹгҖҒ延иҝҹе’Ңиө„жәҗеҚ з”ЁгҖӮ
(дёҖ)жңҖеҲқзҡ„йҖҡйҒ“з»“жһң
VivadoHLSе·Ҙе…·зҡ„иҫ“еҮәз»“жһңеҸҜд»ҘеңЁеҮ з§’й’ҹеҶ…жҳҫзӨәеҮәжқҘпјҢеҰӮеӣҫ7жүҖзӨәпјҡ
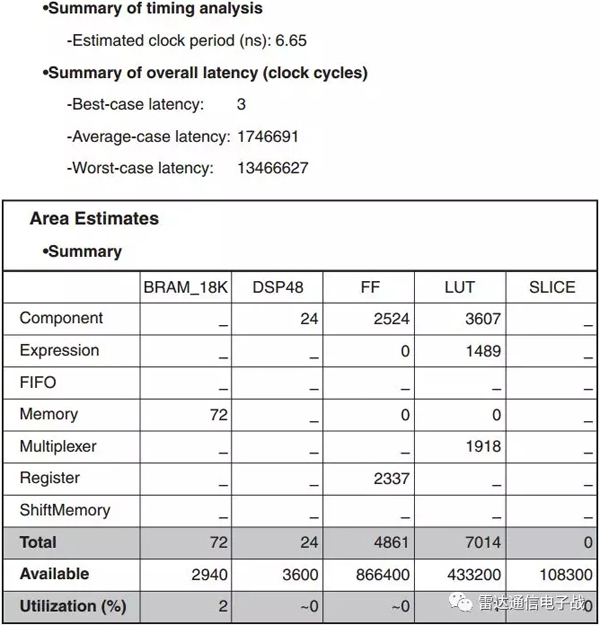
еӣҫ7гҖҒз®—жі•зҡ„第дёҖж¬Ўз»“жһң
йңҖиҰҒжіЁж„Ҹж—¶й’ҹе‘Ёжңҹе’ҢжңҖ差延иҝҹгҖӮеҜ№дәҺзү№е®ҡзҡ„иҝҗз®—пјҢMGS QRD+WBSз®—жі•еӨ§зәҰйңҖиҰҒ10msеҫ—еҮәз»“жһңгҖӮе®ғйҮҮз”ЁDSP48иҠҜзүҮе’ҢRAMжЁЎеқ—гҖӮеҜ№жҹҗдәӣйӣ·иҫҫзі»з»ҹиҖҢиЁҖпјҢиҝҷз§Қ延иҝҹжҳҜеҸҜд»ҘжҺҘеҸ—зҡ„гҖӮ
(дәҢ)йҮҮз”ЁжҢҮд»Өдј йҖ’зҡ„з»“жһң
йҮҮз”Ёзҡ„жҢҮд»ӨиҜҒжҳҺдәҶVivado HLSзҡ„еҠҹиғҪгҖӮеҸӘйңҖз®ҖеҚ•е°ҶCиҜӯиЁҖд»Јз Ғдёӯзҡ„дёҖдәӣFORеҫӘзҺҜеұ•ејҖ16еҖҚпјҢеҜ№RAMжЁЎеқ—иҝӣиЎҢеҲҶеҢәпјҢи®ҫи®ЎиҖ…йҖҡиҝҮPIPELINEжҢҮд»ӨеҸҜд»Ҙеҫ—еҮәд»ӨдәәйңҮжғҠзҡ„з»“жһңпјҢеҰӮеӣҫ8жүҖзӨәгҖӮйҮҮз”ЁC/C++иҜӯиЁҖдҝ®ж”№зҹ©йҳөеӨ§е°ҸеҫҲз®ҖеҚ•пјҢдҪҶеҰӮжһңйҮҮз”ЁHDLдҪңдёәи®ҫи®ЎиҜӯиЁҖпјҢжғ…еҶөе°ұ并йқһеҰӮжӯӨгҖӮ
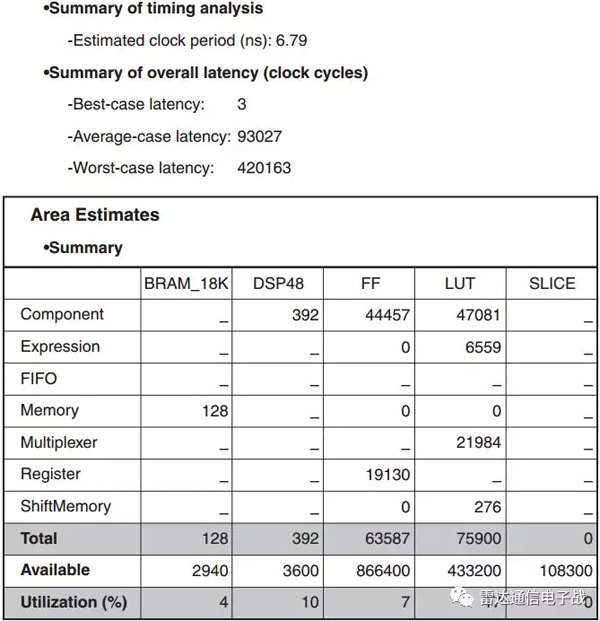
еӣҫ8гҖҒз®—жі•йҮҮз”ЁжҢҮд»ӨеҗҺзҡ„з»“жһң
Xilinxе…¬еҸёзҡ„FPGAиҠҜзүҮзҡ„зәҜDSPеҜҶеәҰжҳҜиҜҘи§ЈеҶіж–№жЎҲзҡ„йҮҚиҰҒжҢҮж ҮгҖӮMGS QRD + WBSз®—жі•еҸӘйҮҮз”ЁдәҶ392дёӘDSP48иҠҜзүҮгҖӮиҝҷдёәиҮӘйҖӮеә”жіўжқҹеҪўжҲҗе’Ңйӣ·иҫҫDSPдҝЎеҸ·еӨ„зҗҶйў„з•ҷдәҶеҫҲеӨ§з©әй—ҙпјҢдҫӢеҰӮи„үеҶІеҺӢзј©гҖҒеӨҡжҷ®еӢ’ж»Өжіўе’ҢжҒ’иҷҡиӯҰзҺҮ(CFAR)гҖӮ
еҰӮеӣҫ9жүҖзӨәпјҢиҝҷжҳҜдёҖйғЁеҲҶCиҜӯиЁҖд»Јз ҒзӨәдҫӢпјҢйҮҚзӮ№жҳҜзј–з ҒйЈҺж је’ҢжҢҮд»ӨгҖӮеҰӮжһңиҝҷж®өд»Јз Ғз”ЁC++иҜӯиЁҖзј–зЁӢпјҢи®ҫи®ЎиҖ…еҸҜд»Ҙи°ғз”ЁеҶ…зҪ®зҡ„еӨҚжқӮж•°еӯҰеҮҪж•°еә“гҖӮеҪ“дёҚйңҖиҰҒиҝӣиЎҢжө®зӮ№иҝҗз®—ж—¶пјҢVivado HLSд№ҹж”ҜжҢҒе®ҡзӮ№иҝҗз®—гҖӮ

еӣҫ9гҖҒжҳҫзӨәзј–з ҒйЈҺж је’ҢжҢҮд»Өзҡ„CиҜӯиЁҖд»Јз ҒзӨәдҫӢ
з”ұдәҺйҮҮз”ЁC/C++иҜӯиЁҖи®ҫи®ЎпјҢеӣ жӯӨжӣҙж”№зҹ©йҳөзҡ„еӨ§е°Ҹйқһеёёз®ҖеҚ•гҖӮйҮҮз”ЁVHDL/Verilogдәәе·Ҙзј–з ҒжҳҜдёҚзҺ°е®һзҡ„гҖӮVivado HLSиҝҳж”ҜжҢҒеӨҡз§ҚжҺҘеҸЈпјҢдҫӢеҰӮFIFOгҖҒRAMжЁЎеқ—гҖҒAXIе’Ңеҗ„з§ҚдҝЎеҸ·дәӨжҚўжҺҘеҸЈгҖӮиҠҜзүҮж ёд№ҹжңүе…Ёж ёжҺ§еҲ¶зҡ„ж—¶й’ҹпјҢеҗҢжӯҘеӨҚдҪҚпјҢејҖе§ӢпјҢе®ҢжҲҗе’Ңз©әй—ІдҝЎеҸ·гҖӮ
е…ӯгҖҒз»“жһң
Virtex-7 1140T FPGAиҠҜзүҮзҡ„Vivado HLSиҪҜ件зҡ„з»“жһңжұҮжҖ»еңЁиЎЁ2дёӯгҖӮиҜҘи®ҫи®ЎжҳҜMGS QRD+WBSз®—жі•иҠҜзүҮж ёпјҢж”ҜжҢҒжңҖеӨҡ128дёӘеҸҳйҮҸиЎҢе’ҢжңҖеӨҡ64дёӘеҸҳйҮҸеҲ—гҖӮ
йҮҮз”ЁVirtex-7 FPGAиҠҜзүҮзҡ„зі»з»ҹжҲҗжң¬жҜ”йҮҮз”ЁARM-A9 CPUиҠҜзүҮзҡ„зі»з»ҹжҲҗжң¬дҪҺеӨ§зәҰ12.5еҖҚгҖӮеҰӮиЎЁ2жүҖзӨәпјҢйҮҮз”ЁXilinxе…¬еҸёзҡ„Vivado HLSе·Ҙе…·пјҢеҸҜд»ҘеңЁ3.3 msеҶ…еӨ„зҗҶ128×64жө®зӮ№еҮҪж•°гҖӮ
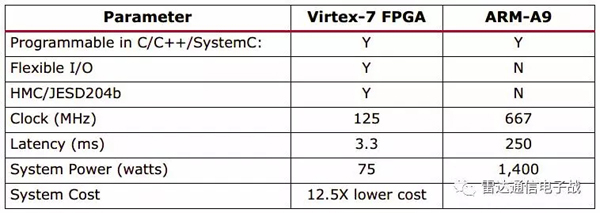
иЎЁ2гҖҒMGS QRD+WBSз®—жі•жҜ”иҫғ
еңЁ667 MHzзҡ„ARM Cortex-A9иҠҜзүҮдёҠжү§иЎҢеҗҢж ·зҡ„д»Јз ҒпјҢдјҡдә§з”ҹ250msзҡ„延иҝҹгҖӮиҝҷз§ҚжҜ”иҫғеҮёжҳҫдәҶдёҖдёӘдәӢе®һпјҢеҚіXilinxе…¬еҸёжңүдёҖеҘ—ж»Ўи¶ідёҖзі»еҲ—и®ҫи®ЎйңҖжұӮзҡ„е®ҢеӨҮзҡ„еҸҜзј–зЁӢйҖ»иҫ‘з»„еҗҲпјҢд»ҺдҪҺ延иҝҹи§ЈеҶіж–№жЎҲеҲ°йҮҮз”ЁARM A9еӨ„зҗҶеҷЁзҡ„й«ҳеәҰйӣҶжҲҗзҡ„Zynq-7000 APSoCи§ЈеҶіж–№жЎҲгҖӮ
з”ЁжҲ·йҮҮз”ЁVivado HLSпјҢж— йңҖйҖҡиҝҮй•ҝж—¶й—ҙзҡ„RTLжЁЎжӢҹпјҢе°ұеҸҜд»Ҙеҝ«йҖҹжӣҙжҚўи®ҫеӨҮгҖҒеҢәеҹҹгҖҒ延иҝҹе’Ңж—¶й’ҹйў‘зҺҮзҡ„з©әй—ҙгҖӮйҮҮз”ЁC/ C++иҜӯиЁҖпјҢеҸҜд»Ҙе°Ҷд»Јз Ғж— зјқй“ҫжҺҘе’Ңж— йҷҗеҲ¶ең°д»ҺXilinxе…¬еҸёзҡ„еҸҜзј–зЁӢйҖ»иҫ‘з»„еҗҲ移жӨҚеҲ°Zynq-7000 AP SoCгҖӮ
иҜҘи®ҫи®ЎйҮҮз”ЁдәҶдёүдёӘжҢҮд»ӨпјҡunrollingгҖҒpipeliningе’ҢRAMжЁЎеқ—еҲҶеҢәгҖӮиҜҘи®ҫи®ЎеӨ§зәҰ4е°Ҹж—¶е®ҢжҲҗпјҢйңҖиҰҒеҜ№жЁЎжӢҹж•°жҚ®иҝӣиЎҢеӨҡж¬Ўз®—жі•жЁЎжӢҹгҖӮиҜҘи®ҫи®ЎеҰӮжһңйҮҮз”ЁVHDL/Verilogдәәе·Ҙзј–з ҒпјҢ并иҝӣиЎҢRTLйӘҢиҜҒпјҢеҸҜиғҪйңҖиҰҒеҮ е‘Ёз”ҡиҮіеҮ дёӘжңҲзҡ„ж—¶й—ҙпјҢеҸ–еҶідәҺи®ҫи®ЎиҖ…зҡ„жҠҖиғҪгҖӮ
дёғгҖҒз»“и®ә
жң¬ж–Үи®әиҝ°дәҶXilinxе…¬еҸёзҡ„FPGAиҠҜзүҮеҸҜд»ҘйҮҮз”ЁVivado HLSеңЁC/C++иҜӯиЁҖдёӯзј–зЁӢпјҢи§ЈеҶідәҶжүҖжңүйӣ·иҫҫжҲ–ж— зәҝзі»з»ҹйқўдёҙзҡ„дёҖйЎ№жңҖеӨҚжқӮзҡ„жҢ‘жҲҳпјҡйҮҮз”ЁMGS QRD+WBSз®—жі•иҝӣиЎҢеӨҚзҹ©йҳөжұӮйҖҶгҖӮ并иЎҢжө®зӮ№иҝҗз®—е’Ңжң¬ең°CиҜӯиЁҖејҖеҸ‘зҡ„еҘҪеӨ„жҳҫиҖҢжҳ“и§ҒгҖӮ
жң¬ең°CиҜӯиЁҖи®ҫи®Ўзҡ„HLSдјҳеҠҝпјҢдҪҝXilinxе…¬еҸёзҡ„FPGAиҠҜзүҮзҡ„жҖ§иғҪе’ҢдҪҺеҠҹиҖ—пјҢдјҳдәҺжүҖжңүFPGAиҠҜзүҮз«һдәүеҜ№жүӢе’ҢCPU/DSP/GPUиҠҜзүҮгҖӮXilinxе…¬еҸёзҡ„7зі»еҲ—FPGAиҠҜзүҮ(еҸҠд»ҘдёҠдә§е“Ғ)пјҢйҮҮз”ЁдәҶе…Ҳиҝӣзҡ„Vivadoе’ҢHLSи®ҫи®ЎжөҒзЁӢпјҢеҗ„дёӘж–№йқўйғҪдјҳдәҺGPUгҖҒDSPе’ҢCPUиҠҜзүҮгҖӮ
жң¬ж–ҮжқҘжәҗXilinxжүӢеҶҢпјҢеұһдәҺз”ЁжҲ·зҝ»иҜ‘еҶ…е®№пјҢдҫӣеӨ§е®¶еҸӮиҖғгҖӮ
 зІӨе…¬зҪ‘е®үеӨҮ 44030902003195еҸ·
зІӨе…¬зҪ‘е®үеӨҮ 44030902003195еҸ·